Deep Learning Revolution
Discover why GPUs, big data, and deep architectures unlocked AI breakthroughs—and the new testing challenges that scale creates.
Overview
Neural networks existed for decades before modern AI took off. The breakthrough wasn't a new algorithm—it was three converging forces: more powerful hardware (GPUs), more training data, and the willingness to stack many layers deep.
This lesson explains why these three ingredients were necessary for AI's recent explosion, and why that scale creates new challenges for QA testing. Understanding this history helps you anticipate where failures can hide in modern systems.
Learning Goals
By the end of this lesson, you'll understand:
- Why shallow neural networks failed despite sound theory
- How GPUs and big data transformed neural networks from theory to practice
- The scaling laws that drive modern AI (bigger = more capable, to a point)
- Why deeper networks introduced new testing and interpretability challenges
- The role of key breakthroughs (ImageNet, AlphaGo, transformers) in QA today
Core Concepts
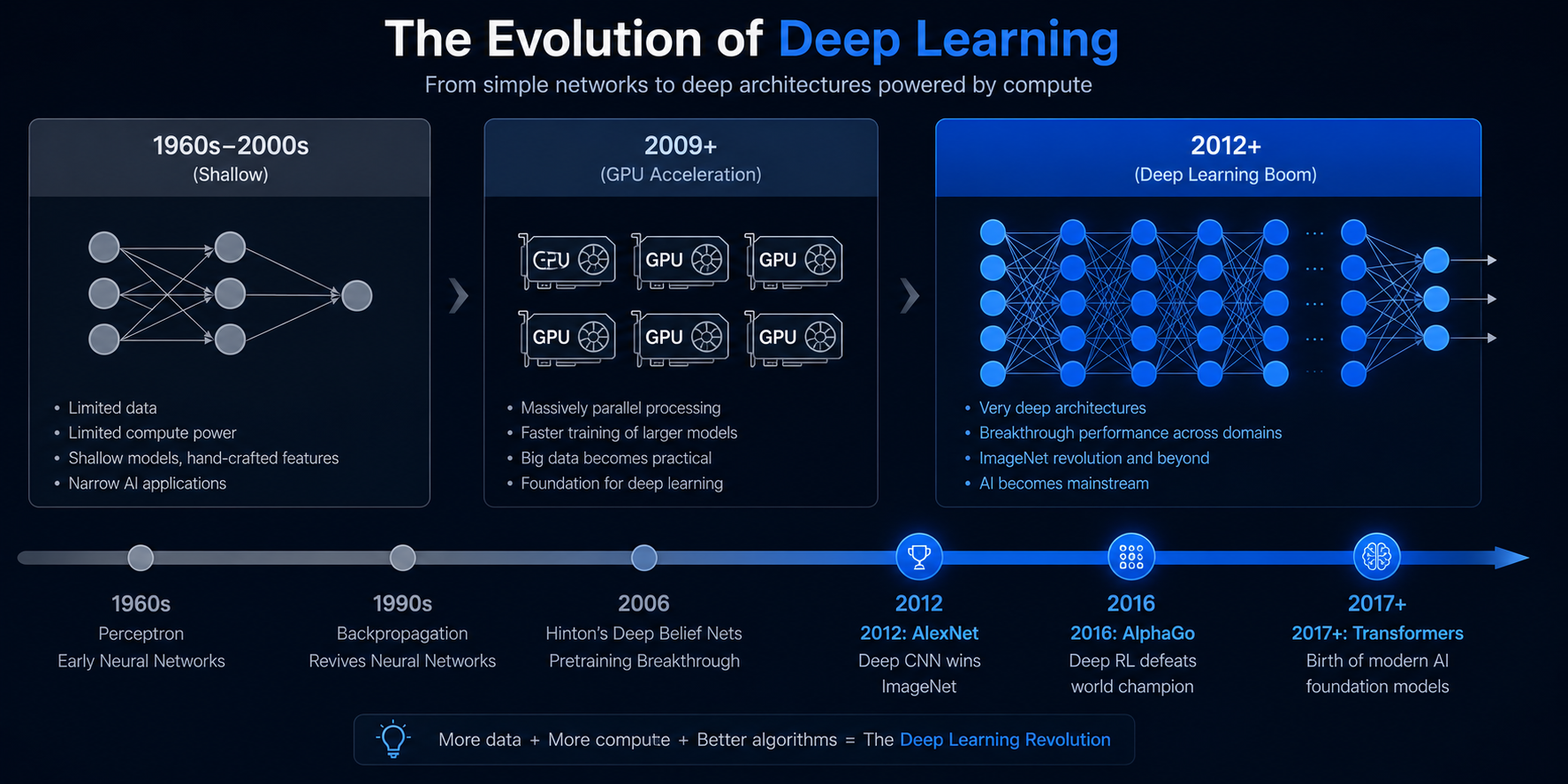
1. The Long Winter: Why Neural Networks Stalled (1970s–2000s)
Neural networks were invented in the 1950s–1960s, but progress stalled. Why?
Reason 1: The XOR Problem In 1969, Minsky and Papert proved that single-layer perceptrons couldn't solve the XOR problem (a simple non-linear task). This was a theoretical blow; people stopped funding neural network research.
Reason 2: Computational Limits Training even modest neural networks required massive computing power. A simple handwritten digit recognizer (LeNet-5, 1998) took 3 days to train on cutting-edge hardware of that time.
Reason 3: Data Scarcity Neural networks need millions of examples to learn well. Large labeled datasets didn't exist in the 1980s–1990s.
Reason 4: The Vanishing Gradient Problem When networks got deeper, backpropagation struggled to propagate error signals through many layers—the gradient would "vanish" before reaching early layers. Deep networks simply wouldn't learn.
Result: The "AI Winter" (1974–1980 and again 1987–1993). Money dried up, researchers moved to symbolic AI and expert systems, and neural networks were largely abandoned.
2. The GPU Revolution: 2004–2012
Everything changed when researchers realized GPUs (graphics processing units) could accelerate neural network training.
Why GPUs?
- Neural network math is matrix multiplication—the same operation graphics cards optimized for rendering
- GPUs have thousands of cores running in parallel; CPUs have just a few
- 100x to 1000x speedup over CPU training for the same network
Key milestone: In 2009, Andrew Ng and Jeff Dean trained a massive neural network (100 million parameters) on 30 NVIDIA GPUs—70x faster than single CPU.
Impact: What took 3 days could now take 1 hour. Researchers could experiment faster, iterate more, and try deeper architectures.
3. The Data Explosion: ImageNet and the 2012 Breakthrough
In 2009, computer vision researchers created ImageNet: a massive database of 14 million labeled images across 1000 categories. For the first time, researchers had a large, standardized benchmark for testing.
In 2012, a team (Krizhevsky, Sutskever, and Hinton) trained a deep convolutional neural network (AlexNet) on ImageNet using GPUs. Its result was dramatic: the model reached a 15.3% top-5 test error, which was 10.8 percentage points lower than the runner-up. That was the moment many teams realized deep learning was not just academic theory anymore.
Why AlexNet mattered:
- Proved that deep networks + GPUs + big data = breakthrough performance
- Used ReLU activation functions (introduced 1969 but overlooked) for fast training
- Showed that handcrafted features were obsolete; networks could learn their own features
This single paper triggered the "deep learning revolution":
- Companies and researchers rushed to apply deep learning
- Computer vision, speech recognition, and machine translation transformed overnight
- Funding flooded back to neural networks
4. Scaling Laws: Bigger Networks, Better Results
A surprising pattern emerged: Scaling up networks improved performance predictably.
The Three Scaling Dimensions:
| Dimension | What It Means | Example |
|---|---|---|
| Model Size | More neurons, more layers | 8 layers → 50 layers → 1000+ layers |
| Data Size | More training examples | 1M images → 1B images |
| Compute | More GPU hours for training | Hours → Days → Weeks |
The Power-Law Idea: Across many training setups, loss often improves in a smooth, power-law-like way as you increase model size, data, or compute. That does not mean every doubling gives the same user-visible quality gain, and it does not mean improvement is free or limitless. It means scaling tends to produce measurable progress if the data, architecture, and optimization are also sound.
Key insight: Scaling usually helps, but the gains are subject to diminishing returns. Each extra jump in compute or model size costs more, and teams still have to balance quality, latency, operating cost, safety, and maintainability.
For QA: This means:
- Models are constantly getting bigger and more capable
- But bigger models can also fail in more subtle, non-obvious ways
- Testing must scale too; you can't manually verify every prediction
Manual QA Perspective
For manual QA, scale changes the job in three important ways:
- You test behaviors, not internal code paths because deep models are opaque
- You prioritize scenarios by user risk because exhaustive checking is impossible
- You look for drift and inconsistency across prompts, formats, languages, and edge inputs
Example: If your product adds an AI-generated defect summary feature, manual QA should compare:
- short bug reports versus long reports
- clean reports versus noisy reports copied from logs
- English-only reports versus mixed-language reports
- harmless prompts versus prompts with confidential data or prompt injection attempts
QA Automation Perspective
For automation engineers and SDETs, scale means the test strategy must become more data-driven:
- build golden datasets and regression suites
- compare results across model versions and prompt versions
- monitor latency, cost, timeout rate, and fallback behavior
- automate safety, policy, and formatting checks
Example automation assertions for a summarization model:
- required fields are always present
- the output stays under the UI character limit
- PII is redacted when policy requires it
- the answer format remains stable enough for downstream parsing
- quality scores on the evaluation set do not drop beyond an agreed threshold
5. Deep Architectures: New Capabilities, New Problems
As networks got deeper (more layers), they gained new capabilities:
Layer-by-Layer Abstraction
- Layer 1: Detects edges and textures
- Layer 2: Detects shapes (circles, corners)
- Layer 3: Detects parts (eyes, noses)
- Layer 8: Detects objects (faces, cars)
- Layer N: Makes predictions (class label)
This hierarchical learning is why "deep" networks excel at complex patterns.
But depth introduced new problems:
Problem 1: Vanishing and Exploding Gradients
In very deep networks, the backpropagation gradient either shrinks (vanishing) or grows (exploding) as it propagates backward. Early layers barely learn.
Solution: Residual connections (ResNet, 2015) skip layers, letting gradients flow directly. This enabled networks with 50, 100, even 1000+ layers.
Problem 2: Interpretability Collapse
Shallow networks were hard to interpret; deep networks are nearly impossible. A decision made in layer 50 of a 100-layer network depends on a complex chain of transformations. Nobody can easily say *why* a network made a specific prediction.
QA Impact: Black box testing becomes critical. You can't trace a bug to a specific layer or neuron; you must infer bugs from output behavior.
Problem 3: Overfitting at Scale
Bigger networks memorize training data instead of learning generalizable patterns. A network with 1 million parameters fit to 1 million training examples will memorize perfectly but fail on new data.
QA Impact: A model might achieve 99% accuracy on a training set but 70% accuracy in production. Your job is to catch this gap early.
6. Key Breakthroughs and Their QA Implications
2012: AlexNet (Computer Vision)
What: Deep CNN for image classification Why it mattered: Proved deep learning worked at scale QA challenge: Now you must test adversarial inputs (tiny perturbations that fool the network)
2016: AlphaGo (Game Playing)
What: Deep RL agent that beat a professional Go player Why it mattered: Showed deep learning could reason, plan, and beat human experts QA challenge: How do you test something that can generate novel strategies? Traditional test cases don't cover all possibilities.
2017: Transformer Architecture (NLP)
What: Attention-based model for language tasks Why it mattered: Enabled GPT, BERT, LLMs—and shifted AI beyond vision into language QA challenge: LLMs generate text non-deterministically. The same prompt can produce different outputs. Testing must account for probabilistic behavior, hallucinations, and biases in training data.
2020+: Large Language Models (GPT-3, GPT-4, etc.)
What: 100B+ parameter language models trained on internet-scale text Why it mattered: Multi-task, few-shot, zero-shot capabilities QA challenge: Millions of emergent behaviors, some unpredictable. No simple way to "test" all capabilities.
7. The Testing Paradox at Scale
As neural networks got bigger and more capable, testing became harder—even though we need it more.
Why?
- Combinatorial explosion: With 1 billion parameters, testing all combinations is impossible
- Emergent behaviors: Large models develop unexpected capabilities not explicitly programmed
- Black box nature: Hard to trace a mistake to a specific root cause
- Statistical nature: Small input changes can produce large output changes (adversarial robustness)
- Bias and fairness: Large models trained on internet data absorb societal biases
New testing approaches emerged:
- Adversarial testing: Deliberately craft inputs to fool the model
- Behavioral testing: Test high-level capabilities (e.g., "can the model summarize?"), not internal weights
- Data quality testing: Validate training and test data for representativeness and bias
- Production monitoring: Watch model performance degrade over time as data distribution shifts
- Human-in-the-loop testing: Use human judgment to catch errors LLMs can't catch themselves
Practical Work: Scaling and QA Readiness
Objective: Understand why bigger models are attractive, then translate that into a realistic QA release strategy.
Exercise Part 1: Simulating Scaling Laws
We'll use publicly available research data to visualize how performance improves with scale.
1import numpy as np2import matplotlib.pyplot as plt34# Simulated scaling law (based on Chinchilla / Compute Optimal research)5# Performance improves as a power law: loss = a / (compute)^b67def loss_from_compute(compute, a=1.0, b=0.07):8 """Model loss as a function of compute budget (FLOPs)."""9 return a / (compute ** b)1011def accuracy_from_loss(loss, baseline_loss=1.0):12 """Convert loss to accuracy (for illustration)."""13 # Assume 100% accuracy at zero loss14 return max(0, 1 - (loss / baseline_loss))1516# Simulate training runs with different compute budgets17compute_range = np.logspace(18, 25, 50) # FLOPs from 10^18 to 10^2518losses = loss_from_compute(compute_range)19accuracies = accuracy_from_loss(losses)2021# Plotting22fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))2324# Plot 1: Loss vs. Compute (log-log scale)25ax1.loglog(compute_range, losses, 'b-', linewidth=2)26ax1.set_xlabel('Compute (FLOPs)', fontsize=12)27ax1.set_ylabel('Loss (lower is better)', fontsize=12)28ax1.set_title('Scaling Law: Loss vs. Compute', fontsize=14)29ax1.grid(True, alpha=0.3)3031# Annotate key milestones32ax1.text(1e20, 0.5, 'GPT-2 era', fontsize=9, alpha=0.7)33ax1.text(1e24, 0.2, 'GPT-4 era', fontsize=9, alpha=0.7)3435# Plot 2: Accuracy vs. Compute (linear scale for clarity)36ax2.plot(compute_range / 1e23, accuracies, 'g-', linewidth=2)37ax2.set_xlabel('Compute (10^23 FLOPs)', fontsize=12)38ax2.set_ylabel('Accuracy', fontsize=12)39ax2.set_title('Model Accuracy Improves with Compute', fontsize=14)40ax2.grid(True, alpha=0.3)41ax2.set_ylim([0, 1])4243plt.tight_layout()44plt.show()4546# Key insight: Printing compute-to-accuracy mapping47print("=== Scaling Law: Accuracy Improves Gradually ===")48for compute_log in [20, 21, 22, 23, 24]:49 compute = 10 ** compute_log50 acc = accuracy_from_loss(loss_from_compute(compute))51 print(f"10^{compute_log} FLOPs → Accuracy: {acc:.1%}")Expected Output
The script demonstrates:
- Log-log relationship: Loss vs. compute shows a straight line (power law)
- Predictable scaling: You can estimate performance at larger scales
- Diminishing returns: Each doubling of compute gives smaller accuracy gains (asymptote toward 100%)
Exercise Part 2: Build a QA Release Checklist for a Larger Model
Imagine your product team wants to replace Model A with a much larger Model B because early demos look better.
Create a QA readiness checklist with these sections:
| Area | What to Check | Example Evidence |
|---|---|---|
| Quality | Does Model B really improve important user tasks? | Eval set comparison, manual review notes |
| Regression Risk | Did any previously good scenarios get worse? | Before/after regression results |
| Safety | Does the larger model introduce new unsafe or non-compliant outputs? | Safety test results, red-team prompts |
| Performance | Can the product still meet latency and timeout targets? | Response-time dashboard, load test |
| Cost | Is the quality gain worth the extra compute cost? | Cost-per-request estimate |
| Operability | Can we monitor and roll back safely? | Dashboards, alerts, rollback plan |
Example QA Scenarios for Manual and Automation Teams
Manual QA scenarios
- ask the same question in several different wordings and compare consistency
- try domain jargon, abbreviations, and typo-heavy prompts
- check whether the larger model becomes more verbose but less precise
- test risky prompts involving confidential data, regulated content, or unsupported claims
Automation QA scenarios
- run a fixed regression dataset against both models and compare pass rates
- compare structured output validity across 100+ runs
- measure p50 and p95 response times
- verify fallback behavior when the model times out or upstream services fail
Reflection Questions
- Testing at Scale: If a company is training a model 1000x bigger than last year's, how should QA testing strategy change? What new failure modes might emerge?
- Cost vs. Capability Trade-off: Bigger models are better but cost more to train and deploy. How might a QA engineer help balance capability improvements with cost?
- Emergent Behaviors: Very large models sometimes develop unexpected behaviors (e.g., GPT-3 writing code despite no explicit training). How would you test for emergent behaviors you don't know about?
- Manual vs. Automation: Which checks in your release checklist should be automated every build, and which still need human review?
Key Takeaways
- Neural networks were abandoned for decades due to computational limits, data scarcity, and the vanishing gradient problem—not because the theory was wrong.
- Three forces unlocked AI: GPU acceleration (2009+), big data (ImageNet, 2009+), and deeper architectures (AlexNet, 2012).
- Scaling laws are remarkably predictable: More compute, more data, more parameters → better performance, in a predictable power law.
- Depth enables abstraction: Layering allows networks to learn hierarchies of increasingly abstract features.
- Deep networks introduced new failure modes: Vanishing gradients, interpretability collapse, overfitting, and emergent behaviors.
- Testing at scale is paradoxical: Bigger, more capable models are harder to test comprehensively, yet more critical to get right.
- Modern QA must evolve: Adversarial testing, behavioral testing, data quality validation, and production monitoring are now essential.
- Release decisions are not accuracy-only: QA must weigh quality, safety, latency, cost, and rollback readiness together.
Next Steps
In the next lesson, "How AI Systems Learn," you'll dive deeper into the training process—how gradient descent actually works, why overfitting happens, and how to spot when a model is learning badly.
Recommended Resources
- Paper: "Attention is All You Need" (2017) – Introduced transformers, foundation of modern LLMs
- Concept: Scaling laws are an active research area; check OpenAI's "Scaling Laws for Neural Language Models" (2020) for deep dives