Neural Networks Made Easy
Use intuitive analogies to understand neurons, layers, training, weights, and bias. Grasp how neural networks learn and why they matter for AI testing.
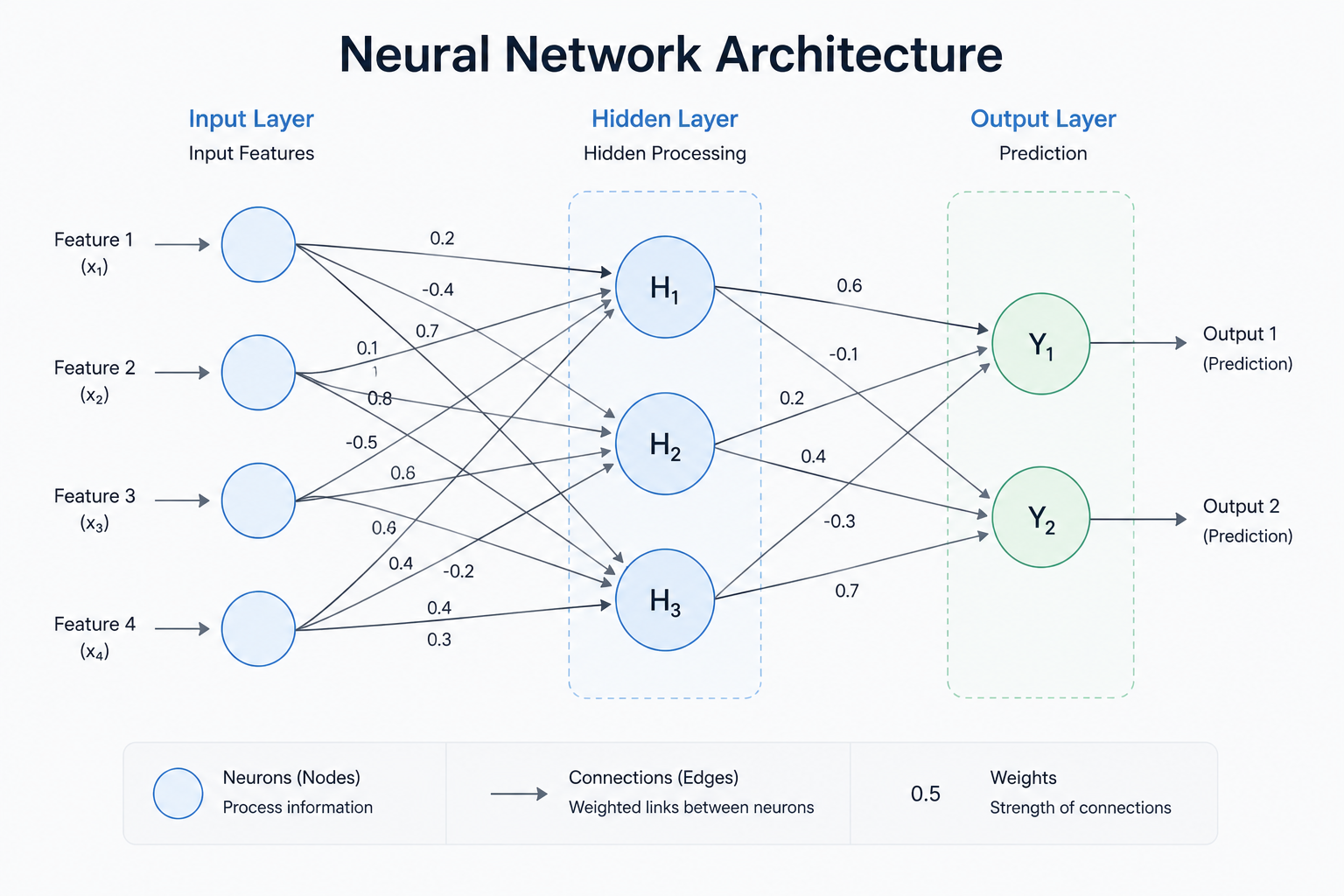
Overview
Neural networks are the foundation of modern AI—including the LLMs, agents, and test automation systems you'll work with as a QA professional. Despite their mathematical complexity, the core idea is remarkably simple: neurons learn to recognize patterns by adjusting their connection strength (weights) based on examples.
In this lesson, you'll build an intuitive understanding of how neurons work, how they organize into layers, and why that architecture enables AI systems to learn. You'll see why testing these systems requires understanding how they make decisions—and where mistakes can happen.
Beginner note: If you do not want to go deep into the mechanics, you can safely focus on the high-level idea and skim the more technical parts. The key takeaway is simple: a neural network is a pattern-learning system. It takes inputs, passes them through connected layers, and produces an output such as a classification, score, or prediction. As a QA professional, you do not need to memorize the math. You need to understand that these systems learn from data, can behave differently on edge cases, and must be validated carefully rather than trusted automatically.
Learning Goals
By the end of this lesson, you'll be able to:
- Explain what an artificial neuron is and how it mimics biological learning
- Describe how layers of neurons stack to process complex patterns
- Understand the role of weights, bias, and activation functions in neural computation
- Recognize why "black box" concerns matter for AI QA
- Identify where neural networks succeed and fail—critical for test strategy
Core Concepts
1. The Artificial Neuron: A Simple Decision Maker
An artificial neuron is the smallest building block of a neural network. Think of it as a tiny decision-maker that:
- Receives inputs from data or other neurons (e.g., pixel brightness in an image, or word embeddings in text)
- Weights each input by multiplying it by a strength value (the "weight")
- Adds them up plus a bias term (a constant that shifts the decision boundary)
- Applies an activation function to produce an output
Here's the formula:
Where:
- = weight for input
- = input
- = bias
- = a non-linear function (e.g., ReLU, sigmoid)
Real-world analogy: Imagine a quality checklist. Each item (input) has a priority weight. You add them up, compare to a threshold (bias), and decide: "pass" or "fail."
2. Weights and Bias: The Learnable Parameters
Weights are the connection strengths between neurons. When a weight is large, that input has a big influence; when it's small, that input barely matters.
Bias is a learnable constant that shifts the decision boundary. It lets the neuron fire even when all inputs are zero—critical for learning complex patterns.
During training, an algorithm adjusts these weights and biases so that the neuron makes fewer mistakes on real data. This is where neural networks "learn."
QA Insight: When you test an AI model, bugs often stem from weights that were optimized for the training data but fail on edge cases (new data it never saw). Understanding this helps you design better test scenarios.
3. Activation Functions: Injecting Non-Linearity
Without activation functions, stacking neurons would just compute linear equations—useless for learning complex patterns. Activation functions add non-linearity, enabling networks to learn curves, relationships, and hierarchies.
Common activation functions:
| Function | Formula | When Used | Behavior |
|---|---|---|---|
| ReLU (Rectified Linear Unit) | Hidden layers (most common) | Zero out negative values; fast to compute | |
| Sigmoid | Binary classification output | Outputs range 0–1 (probability-like) | |
| Tanh | Hidden layers, RNNs | Outputs range -1–1 |
QA Insight: Different activation functions can produce different predictions on the same input. Testing model behavior at the boundary of these functions can reveal edge cases.
4. Layers: Building Complexity Through Abstraction
A single neuron makes simple decisions. Multiple neurons in one layer can learn multiple patterns in parallel. Multiple layers can learn hierarchies of patterns.
Example: An image recognition network might have:
- Input layer: Raw pixel values
- Layer 1 (edges): Neurons detect simple features like lines and curves
- Layer 2 (shapes): Neurons recognize combinations of edges (circles, corners)
- Layer 3 (objects): Neurons recognize full objects (faces, cars)
- Output layer: Classification (e.g., "cat" vs. "not cat")
This hierarchical learning is why deep networks (many layers) can solve complex problems, and why "deep learning" is called "deep."
QA Insight: This layered processing means that errors can compound. A mistake in layer 1 (edge detection) propagates through layer 2 (shape recognition). Testing intermediate outputs—not just the final prediction—helps catch cascading failures.
5. Training: The Learning Algorithm
Networks don't start out smart. They begin with random weights and bias. Training adjusts them through a process called backpropagation:
- Forward pass: Feed data through the network, compute predictions
- Compare to reality: Measure the error (e.g., how far off the prediction was)
- Backward pass: Calculate how much each weight contributed to the error
- Adjust weights: Nudge weights in the direction that reduces error
- Repeat: Do this thousands or millions of times until the network's error is acceptably low
The key insight: Backpropagation assigns blame. If a prediction was wrong, which weights were most responsible? Adjust them.
QA Insight: After training, a model is "frozen"—weights stop changing. But testing still matters because:
- The model saw only training data; it may fail on new, unseen cases (overfitting)
- Edge cases (extreme values, rare patterns) might not be well-represented in training data
- Deployment environments may differ from training (different hardware, input distributions, etc.)
6. Why Neural Networks Matter for QA
Supervised Learning + Human Labels
Neural networks require examples to learn from. The quality of those examples directly affects model behavior. As a QA professional, you must ensure:
- Training data is representative and high-quality
- Labeling is consistent and accurate
- Models don't memorize training data (overfitting)
The "Black Box" Problem
Neural networks are notoriously hard to interpret. You can't easily ask a network, "Why did you predict X?" This makes testing harder:
- You can't verify logic step-by-step
- Errors may be subtle and context-dependent
- You must rely on systematic testing across many scenarios
Failure Modes Are Non-Obvious
Unlike traditional software, neural networks can fail in unexpected ways:
- Adversarial examples: Tiny perturbations that fool the model (e.g., altering a few pixels in an image)
- Distributional shift: The model was trained on cats with sunny backgrounds; it fails when tested on rainy-day cats
- Cascading errors: A mistake in layer 1 compounds through deeper layers
- Hallucinations: Large language models "generate plausible-sounding but false information"
Manual QA Perspective
If you are a manual QA professional, neural network knowledge helps you design better exploratory tests:
- Boundary thinking: Try inputs that are almost valid, partially valid, or ambiguous
- Variation testing: Change one thing at a time to see whether the prediction flips unexpectedly
- Expectation management: Sometimes the right test oracle is not "exact answer" but "acceptable behavior range"
- Risk-based coverage: Focus first on high-impact failure cases such as unsafe outputs, biased outputs, and inconsistent decisions
Example: If a support-ticket classifier labels tickets as "Billing", "Technical", or "Urgent", a manual QA tester should try:
- short inputs versus long inputs
- typo-heavy inputs
- mixed-intent inputs such as "payment failed and app crashed"
- emotionally charged or unclear wording
- domain terms the model may not have seen often
QA Automation Perspective
If you are a QA automation engineer or SDET, neural networks change how you automate validation:
- Assert ranges and properties, not exact strings only
- Create curated evaluation datasets with expected labels or expected behavioral criteria
- Track regressions across model versions instead of relying on one-off checks
- Separate deterministic tests from probabilistic tests so flaky expectations do not pollute the suite
Example automation checks for an AI classifier:
- given 100 curated samples, accuracy must stay above an agreed threshold
- toxic or sensitive prompts must trigger safe handling
- repeated runs must stay within acceptable variance
- latency and timeout behavior must still meet product expectations
A Simple QA Checklist for Neural Network Features
Before release, ask:
- What kinds of inputs was the model trained on?
- What real-world inputs are likely missing from that data?
- What is the worst business impact of a wrong prediction?
- Which cases require human review or escalation?
- How will we detect quality drift after deployment?
Practical Work: Exploring Neural Network Behavior Through a QA Lens
Objective: Understand how weights, bias, and activation functions influence neuron output, then translate that understanding into QA test design.
Exercise Part 1: The Neuron Simulator
Using simple Python, let's simulate a single neuron's behavior:
1import numpy as np2import matplotlib.pyplot as plt34# Define a single neuron with 2 inputs5def neuron_output(inputs, weights, bias, activation='relu'):6 """7 Compute the output of a neuron.8 inputs: array of input values9 weights: array of weights (one per input)10 bias: scalar bias term11 activation: 'relu', 'sigmoid', or 'linear'12 """13 # Weighted sum14 z = np.dot(inputs, weights) + bias15 16 # Apply activation function17 if activation == 'relu':18 return np.maximum(0, z)19 elif activation == 'sigmoid':20 return 1 / (1 + np.exp(-z))21 elif activation == 'linear':22 return z23 else:24 raise ValueError("Unknown activation")2526# Test Case 1: How do weights affect output?27inputs = np.array([2.0, 3.0])28bias = 0.52930print("=== Test 1: Varying Weights ===")31for w1 in [0.1, 0.5, 1.0, 2.0]:32 weights = np.array([w1, 0.5])33 output = neuron_output(inputs, weights, bias, 'linear')34 print(f"Weights={weights}, Output={output:.2f}")3536# Test Case 2: How does bias shift the output?37weights = np.array([0.5, 0.5])38print("\n=== Test 2: Varying Bias ===")39for b in [-1.0, 0.0, 1.0, 2.0]:40 output = neuron_output(inputs, weights, b, 'linear')41 print(f"Bias={b}, Output={output:.2f}")4243# Test Case 3: Activation function behavior44print("\n=== Test 3: Activation Functions ===")45test_z_values = [-2.0, -1.0, 0.0, 1.0, 2.0]46for z in test_z_values:47 fake_inputs = np.array([z])48 fake_weights = np.array([1.0])49 50 relu_out = neuron_output(fake_inputs, fake_weights, 0, 'relu')51 sigmoid_out = neuron_output(fake_inputs, fake_weights, 0, 'sigmoid')52 53 print(f"Z={z:5.1f} | ReLU={relu_out:6.3f} | Sigmoid={sigmoid_out:6.3f}")Expected Output
The script demonstrates:
- Larger weights → larger output values (higher sensitivity to that input)
- Bias shifts the output uniformly (higher bias = higher baseline output)
- Activation functions constrain the output (ReLU zeros out negatives; sigmoid keeps output between 0–1)
Exercise Part 2: Turn the Concept into a QA Test Plan
Imagine your team ships an AI feature that classifies incoming bug reports into:
UI issueBackend issueTest environment issueNeeds human triage
Create a small test matrix with at least 12 test cases covering:
- clear examples
- ambiguous examples
- mixed-signal examples
- typo-filled examples
- unusually short inputs
- unusually long inputs
For each case, record:
- input text
- expected label or acceptable label range
- why this case matters
- what kind of neural-network weakness it is probing
Example Starter Cases
| Input | Expected Behavior | Why It Matters |
|---|---|---|
| "Login button overlaps footer on iPhone 13" | UI issue | Clear, clean happy-path example |
| "Checkout failed after API timeout" | Backend issue or Needs human triage | Mixed UI and backend signals |
| "env broken no mail send" | Test environment issue or Needs human triage | Tests typo tolerance and vague phrasing |
| "Everything is failing in staging after deployment" | Needs human triage | High ambiguity, high business impact |
Reflection Questions
- Overfitting Insight: If a network has very large weights, it might fit training data perfectly but fail on new data. Why? (Hint: Large weights = high sensitivity to input details.)
- Edge Case Testing: If a model uses sigmoid activation, its output range is 0–1. What happens if you input values far outside the training range? Why is this important for testing?
- Black Box Concern: Even with this simple neuron, can you predict the output without running the code? How would this get exponentially harder with millions of neurons and unknown weights?
- QA Translation: Which of your test cases would you automate first, and which would you keep for exploratory testing by a human tester?
Key Takeaways
- Artificial neurons are learnable decision-makers: They receive weighted inputs, add a bias, apply an activation function, and output a decision.
- Weights encode learned patterns: Large weights mean "this input is important"; small weights mean "ignore this."
- Activation functions enable non-linearity: Without them, stacking neurons wouldn't add power.
- Layers build hierarchies: Each layer abstracts patterns from the previous layer, enabling complex learning.
- Training adjusts weights through backpropagation: Errors are used to nudge weights in better directions.
- Neural networks fail in non-obvious ways: Testing must cover edge cases, distributional shifts, and adversarial scenarios—not just happy paths.
- QA must test, not trust: Understanding weights, biases, and activation functions helps you design tests that catch real-world failures.
- Manual QA and automation both matter: Human exploration finds ambiguity and risk; automation provides scalable regression coverage.
YouTube Resources
Why watch this: This is one of the clearest visual explanations of neurons, layers, weights, bias, and activations. It matches the level and mental model used in this lesson.
Why watch this: This is the best follow-up if you want to understand how weights actually get updated during training without jumping into heavy math too quickly.
Next Steps
In the next lesson, "Deep Learning Revolution," you'll see how stacking many layers and scaling to massive networks led to the AI breakthroughs we see today—and the new testing challenges that arise at scale.