Transformers and Attention
Learn self-attention, transformer layers, and why this architecture made modern LLMs fast, scalable, and context-aware.
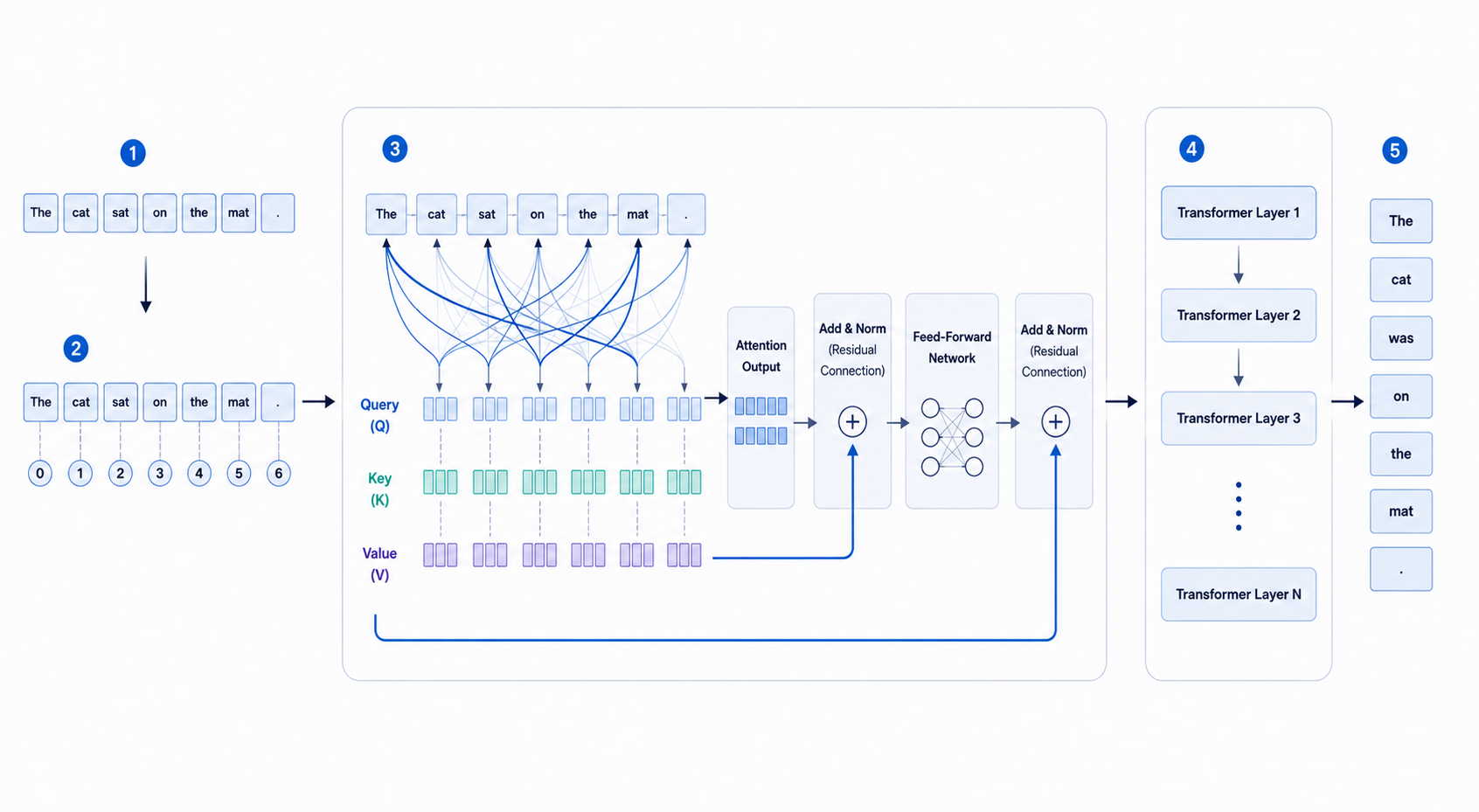
Overview
Transformers are the architecture behind most modern LLMs. Their key breakthrough was attention: a way for each token to look at other relevant tokens in the sequence without relying on older recurrent processing patterns.
For QA professionals, transformer knowledge is useful because many real-world failures come from context handling, prompt order effects, long-input degradation, or weak retrieval integration. Those behaviors are easier to reason about when you understand attention at a practical level.
A Practical Note for QA Learners
You do not need to become a machine learning engineer to benefit from this lesson. What matters most here is understanding why prompt order, nearby context, and long inputs can change model behavior in ways that feel surprising from a normal software-testing perspective.
If the math feels heavy, focus on the intuition:
- tokens pay attention to other relevant tokens
- prompt structure changes what the model notices
- weak context design can create quality problems even when the model is powerful
Learning Goals
- Explain why transformers replaced older sequence models for modern LLMs.
- Understand self-attention in plain language.
- Recognize the role of queries, keys, values, and positional information.
- Connect transformer behavior to prompt ordering and context quality.
- Design QA checks that target attention-related weaknesses.
Core Concepts
1. Why Older Sequence Models Struggled
Before transformers, many NLP systems used recurrent neural networks or LSTMs. Those models process sequences step by step, which made long-range dependencies harder and training less parallelizable.
The transformer paper proposed an architecture based primarily on attention, removing recurrence and making training much more parallelizable.
2. Self-Attention in Plain Language
Self-attention lets each token decide which other tokens matter for interpreting its meaning.
Example:
- In the sentence "The test failed because it timed out," the word "it" should pay attention to "test" rather than every token equally.
That selective focus is the core idea.
3. Queries, Keys, and Values
In self-attention, each token representation is transformed into:
- a query: what this token is looking for
- a key: what this token offers
- a value: the information carried forward
The model compares queries and keys to decide attention weights.
A simplified attention formula is:
You do not need to memorize the math. The important idea is:
- higher relevance between tokens gives higher attention weight
- the weighted values become the token's updated contextual meaning
4. Positional Information Matters
Transformers do not inherently know token order. They need positional information so that "dog bites man" and "man bites dog" are treated differently.
That is why position encoding or equivalent positional mechanisms are essential.
QA implication:
- changing prompt order can materially change model behavior
- retrieved context placed too late or in a noisy block may be ignored or underweighted
5. Multi-Head Attention and Stacked Layers
Modern transformers use multiple attention heads so the model can attend to different relationship types at once.
One head may focus more on:
- syntax
- nearby dependencies
- long-range references
- entity relationships
Stacking many layers allows the representation to become more contextual and more abstract over time.
6. Why Transformers Scaled So Well
Transformers made modern LLMs practical because they:
- parallelize training better than recurrent approaches
- handle long-range context more effectively
- work well with very large datasets and parameter counts
- support transfer from general pretraining to many downstream tasks
7. What Attention Means for QA
Attention is powerful, but it does not guarantee perfect retrieval or reasoning.
Common QA-relevant behaviors:
- the model over-focuses on early prompt content
- critical rules in the middle of a long prompt are ignored
- conflicting instructions produce inconsistent priority handling
- noisy logs or irrelevant retrieved passages distract the model
8. What QA Teams Should Actively Probe
Useful transformer-related checks include:
| Risk area | What to test | Example |
|---|---|---|
| Prompt order sensitivity | Move key rules earlier or later | Check whether coupon or retry rules disappear in a checkout test prompt |
| Context distraction | Mix useful and irrelevant text | Add noisy logs and confirm the model still uses the real requirement |
| Conflict handling | Provide competing instructions | See which instruction wins and whether the choice is consistent |
| Long-context degradation | Increase input size gradually | Compare output quality near realistic context boundaries |
QA/SDET Relevance
Manual QA should test:
- prompt order sensitivity
- hidden conflicts between instructions
- long-context scenarios with both relevant and irrelevant data
- whether the model uses the right evidence from provided text
QA automation and SDET workflows should test:
- retrieval ranking quality before generation
- prompt-template changes that accidentally bury key constraints
- output drift when additional context is appended
- citation or groundedness checks for answer-with-evidence flows
Practical Work
Exercise: Prompt Order and Attention Experiment
Objective: Observe how prompt order changes model behavior.
Use the same task in three different prompt layouts.
Task:
1Generate regression test ideas for a checkout flow.2Business rules: coupon optional, payment retry up to 3 times, guest checkout allowed, order confirmation email required.Prompt variants:
- Put the business rules first.
- Put the business rules last after lots of extra context.
- Insert distracting irrelevant notes between the rules.
Measure:
- which rules appear in the output
- whether the output quality drops
- whether the model invents missing constraints
Reflection:
- Which rule was dropped most often?
- Did prompt length reduce coverage quality?
- How would you turn this into an automated regression check?
Key Takeaways
- Transformers replaced older sequence models by making attention central.
- Self-attention lets tokens weight other tokens based on relevance.
- Queries, keys, values, and positional information drive contextual understanding.
- Prompt order and context quality directly affect LLM performance.
- QA should test for attention-related issues such as buried constraints and noisy context.
YouTube Resources

What this helps with: The best visual explanation of attention and transformer flow for beginners who want intuition before code.

What this helps with: Connects the theory to implementation details and helps technical QA engineers understand what the model pipeline is actually doing.
Next Step
Next, continue with How ChatGPT Works to connect LLM building blocks to the real prompt-to-response behavior users see in production tools.