How ChatGPT Works
Follow the prompt-to-response workflow including tokenization, embeddings, transformers, alignment, and RLHF.
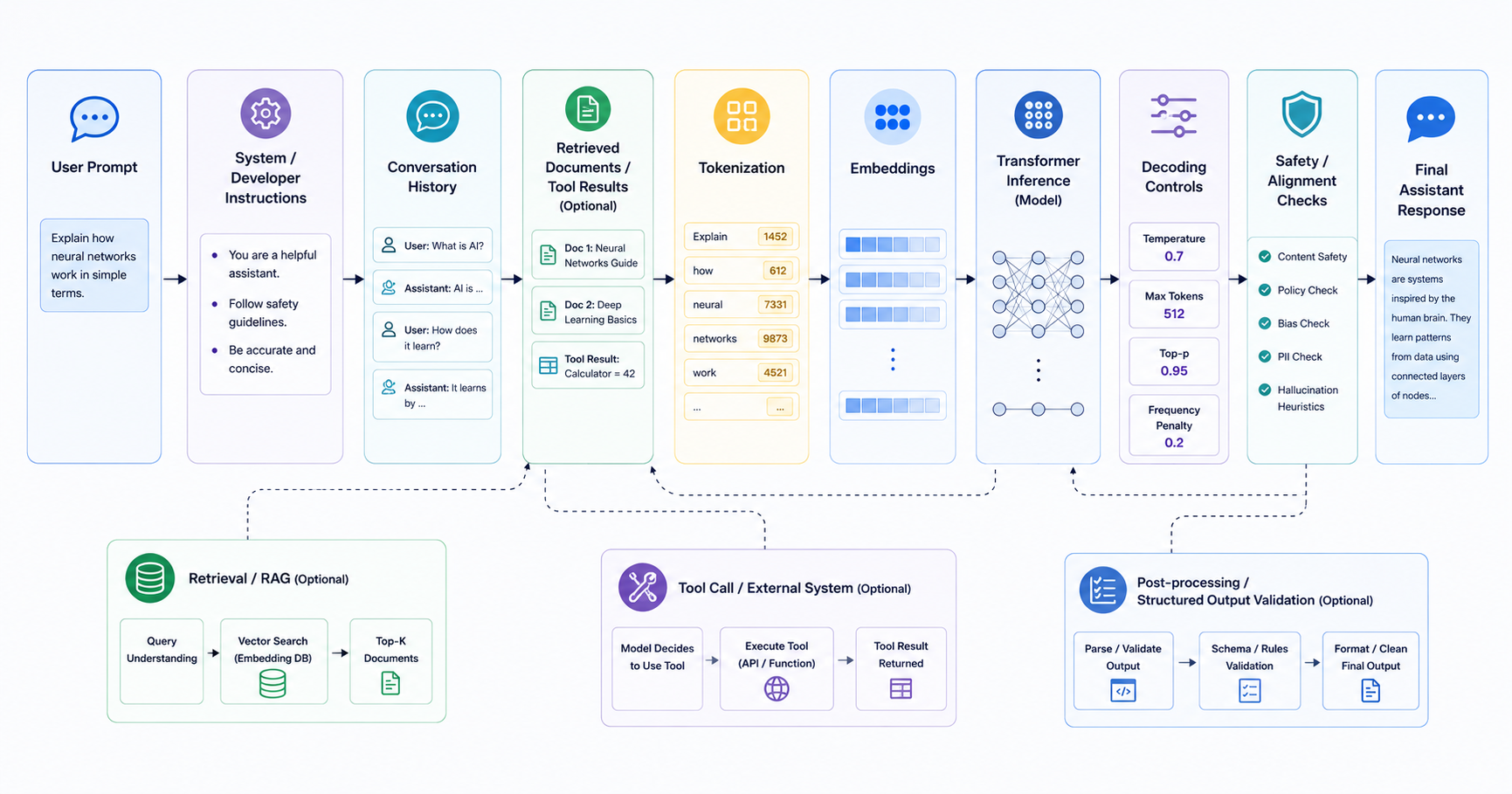
Overview
When people say "ChatGPT works like a chatbot," they are only describing the interface. Under the hood, a ChatGPT-style system is a layered workflow: role instructions, conversation state, tokenization, transformer inference, decoding, post-processing, and sometimes tools or memory.
For QA teams, this matters because bugs can come from many places besides the base model itself. A failure may be caused by prompt assembly, truncated context, wrong role ordering, unsafe tool output, or a decoding setting that changes consistency. This lesson breaks down that prompt-to-response path so you can test the full system, not just the model brand.
A Practical Note for QA Learners
This lesson is less about memorizing internal AI terminology and more about learning where failures can happen in a chat-style system. If you already use tools like ChatGPT or Claude, the practical goal is to stop treating a bad answer as "just an AI issue" and start locating the likely failure layer more precisely.
Focus on these three ideas:
- a chat assistant is a system, not only a model
- prompt assembly and context handling are often part of the bug
- retrieval, tools, and post-processing can fail even when the base model is fine
Learning Goals
- Trace the path from user prompt to assistant response.
- Understand the role of instructions, messages, and conversation state.
- Explain where tokenization, inference, and decoding happen.
- Recognize where alignment and RLHF influence behavior.
- Build QA checks for chat-style AI workflows.
Core Concepts
1. A Chat App Is More Than a Raw Model Call
A ChatGPT-style system usually includes:
- application-level instructions or policies
- user input and chat history
- optional retrieved context or tool output
- the LLM itself
- decoding settings
- output filtering or post-processing
That means "the model answered badly" is often an incomplete diagnosis.
2. Message Roles and Instruction Priority
Modern chat systems often structure input as messages with roles such as:
- system or developer
- user
- assistant
These roles matter because they shape instruction priority. Model behavior can change significantly if:
- a business rule is placed in the wrong message role
- previous conversation turns are omitted
- the prompt is formatted differently than the model expects
Practical QA implication:
- Test the same request with changed role placement to uncover integration bugs.
3. Tokenization and Chat Formatting
Even chat models still continue a token sequence under the hood. Chat templates convert messages into the specific token pattern the model was fine-tuned on.
This is why wrong formatting can degrade output quality. A model may expect special markers or a certain role structure, and if the application builds the prompt incorrectly, quality can collapse without obvious errors.
4. Inference: Generating One Token at a Time
Once the input is assembled, the model processes the tokenized sequence and predicts the next token distribution. It then generates one token, adds it to context, and repeats.
This loop continues until:
- a stop token is reached
- a maximum token limit is reached
- a tool call or structured output condition changes flow
Important implication:
- the model does not plan the full final answer in one perfect step
- early token choices influence later output quality
5. Decoding Controls Shape the Personality of the Output
The same model can feel very different depending on generation settings.
| Setting | Effect | QA concern |
|---|---|---|
| Temperature | More or less randomness | Stability across runs |
| Max tokens | Limits output length | Truncation of important detail |
| Top-k / top-p | Restricts candidate tokens | Creativity vs consistency trade-off |
| Stop conditions | Ends output early | Broken schemas or cut-off explanations |
6. Alignment and RLHF
After pretraining, many chat systems are further shaped through methods such as:
- instruction tuning
- supervised fine-tuning
- reinforcement learning from human feedback
- safety filters and refusal policies
These help the system become more useful, safe, and consistent for chat use.
However, they can also introduce trade-offs:
- over-refusal for legitimate prompts
- bland or generic answers
- inconsistent behavior near policy boundaries
7. Tool Use, Retrieval, and Hidden Failure Points
Many production chat assistants are not just text generators. They may call tools, retrieve documents, or compose answers from external data.
That creates additional failure surfaces:
- wrong retrieval result
- tool timeout
- stale external data
- unsafe tool output passed back into the prompt
- poor answer synthesis after retrieval
8. A Useful QA Debugging Mindset for Chat Systems
When a chat assistant fails, ask these questions in order:
- Did the application send the right instructions and context?
- Was important information truncated or buried?
- Did the model misinterpret the prompt or ignore a constraint?
- Did decoding settings make the answer unstable?
- Did retrieval, tool calls, or post-processing introduce the real error?
This mindset helps QA teams separate model problems from integration problems more quickly.
QA/SDET Relevance
Manual QA should test:
- message history handling
- context truncation behavior
- prompt-role mistakes
- refusal boundary consistency
- groundedness when external data is included
Automation and SDET workflows should test:
- prompt assembly deterministically
- schema validity for structured outputs
- retries and fallback logic on timeout or tool failure
- stable behavior on a regression prompt set
- monitoring signals such as latency, refusal rate, and hallucination rate
Practical Work
Exercise: Map the Failure Surface of a Chat Assistant
Objective: Treat a chat AI feature like a distributed system with multiple failure points.
Pick a QA use case such as "Generate test cases from acceptance criteria."
Create a workflow map with these stages:
| Stage | Example risk | Example test |
|---|---|---|
| Prompt assembly | Missing rule in developer message | Compare raw prompt before send |
| Tokenization/context | Long requirement gets truncated | Near-limit prompt test |
| Model inference | Hallucinated constraints | Gold-set evaluation |
| Decoding | Output becomes inconsistent | Repeat-run variability check |
| Post-processing | JSON parsing failure | Schema validator |
| Retrieval or tools | Wrong source used | Groundedness and citation check |
Then write one test case per stage.
Reflection:
- Which failures belong to the model versus the application layer?
- Which of these checks should run in CI?
- Which failures would a user see first in production?
Key Takeaways
- ChatGPT-style systems combine prompt assembly, model inference, and application logic.
- Role formatting and conversation state strongly influence quality.
- Responses are generated token by token, so decoding settings matter.
- Alignment improves usefulness and safety but can introduce new edge cases.
- QA should test the whole chat workflow, not only the underlying model.
YouTube Resources

What this helps with: Connects model internals to the actual user experience of modern chat systems and explains many practical failure modes.

What this helps with: Gives a cleaner prompt-to-response system view of ChatGPT, including where context, model inference, and safety layers show up in practice.
Next Step
Next, continue to Level 5 on Prompt Engineering Fundamentals, where you will turn these internal concepts into repeatable prompting and evaluation techniques.