Understanding LLMs
Cover tokens, parameters, context windows, embeddings, transformers, and model families.
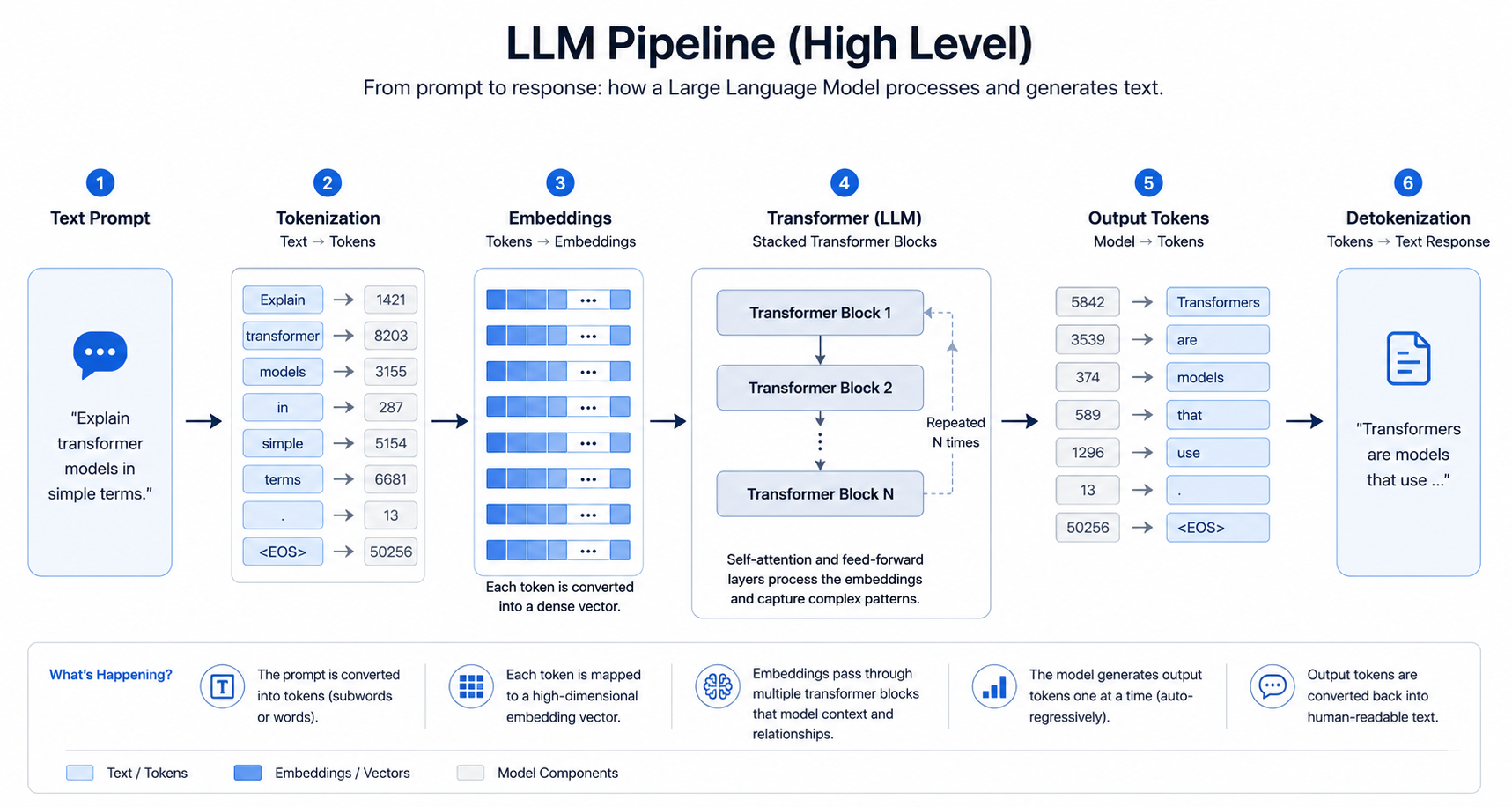
Overview
Large language models, or LLMs, are the systems behind tools like ChatGPT, Claude, Gemini, and Copilot. They do not store finished answers like a database. Instead, they process input as tokens, represent those tokens as vectors, and generate responses one token at a time using patterns learned during training.
For QA professionals, an LLM is not just an AI buzzword. It is a probabilistic software component with input limits, formatting expectations, model-specific behavior, and very real failure modes. This lesson gives you the mental model you need before going deeper into transformer internals and ChatGPT-style workflows.
A Practical Note for QA Learners
If this lesson starts to feel overly technical, do not worry about memorizing every term. The most important mental model is that an LLM is a text-processing system with limits, probabilities, and context rules rather than a source of guaranteed truth.
For practical QA work, three things matter most:
- The model only sees what fits into its current context window.
- The same task can behave differently depending on prompt wording and decoding settings.
- Good QA focuses on behavior, consistency, and failure patterns, not only whether one answer "looks smart."
Learning Goals
- Explain what an LLM is in plain language.
- Distinguish tokens, parameters, embeddings, and context windows.
- Recognize the main model families and why they behave differently.
- Understand why outputs are probabilistic rather than fully deterministic.
- Translate LLM concepts into concrete QA and SDET testing strategy.
Core Concepts
1. What Makes a Model an LLM?
An LLM is a deep learning model trained on very large amounts of text so it can predict likely next tokens in a sequence. Modern LLMs are typically built on transformer architecture and are useful for many language tasks without needing separate models for each task.
In practical terms, that means one model may be able to:
- summarize release notes
- draft API tests
- explain a stack trace
- rewrite a defect report for clarity
- generate structured JSON
That versatility is why LLMs matter so much in QA workflows.
2. Tokens: The Real Unit of Input and Output
Humans think in words and sentences. LLMs process tokens.
A token can be:
- a whole word
- part of a word
- punctuation
- whitespace pattern
Why this matters:
- context limits are measured in tokens, not pages
- prompt cost is often measured in tokens
- long logs or requirements can overflow the available context window
Example:
- A short sentence may become 10 to 20 tokens.
- A large bug report with logs may become thousands of tokens.
QA implication:
- If a prompt silently truncates important context, the model may still answer confidently but miss the real issue.
3. Parameters and Embeddings
Parameters are the learned numeric weights inside the model. More parameters often increase capacity, but parameter count alone does not guarantee better quality for your use case.
Embeddings are vector representations of tokens or text. They let the model treat language as geometry in a high-dimensional space, where similar meanings can land closer together.
Practical intuition:
- tokens are the pieces
- embeddings are the numeric representation of those pieces
- parameters are the learned rules for transforming those representations
Manual QA angle:
- similar prompts can still behave differently because the model is sensitive to wording, order, and hidden structure in the token sequence.
QA automation / SDET angle:
- regression suites should track behavior, not just the published parameter count or marketing claims for a model.
4. Context Windows: What the Model Can See at Once
The context window is the maximum number of tokens the model can use at one time. That usually includes:
- system or developer instructions
- user messages
- retrieved documents
- tool outputs
- the generated answer itself
This is one reason prompt engineering and retrieval design matter so much. If the relevant information is not in the current context, the model cannot reliably use it.
QA implication:
- Large-context support does not guarantee good long-context reasoning.
- You should test near the context boundary with realistic data sizes.
5. Base Models, Instruct Models, and Chat Models
Not all LLMs are trained for the same interaction style.
| Model type | What it is optimized for | QA-relevant behavior |
|---|---|---|
| Base model | Raw next-token continuation | Often less safe, less instruction-following |
| Instruct model | Following direct instructions | Better for task completion |
| Chat model | Conversational multi-turn exchange | Better dialogue flow, role handling, and assistant behavior |
This distinction matters because a model can be technically strong and still perform poorly if you use the wrong prompt format for its training style.
6. Decoder Behavior: Why Outputs Vary
At inference time, the model predicts a probability distribution over possible next tokens. The application or inference engine then chooses one.
Common generation controls include:
- temperature: higher values increase randomness
- top-k: limit selection to the top-k candidates
- top-p: limit selection to the smallest set whose cumulative probability reaches a threshold
- max_new_tokens: limit output length
This is why the same prompt can produce different valid answers across runs.
QA implication:
- Exact string matching is often the wrong oracle.
- Property-based checks, schema validation, and rubric scoring are more robust.
7. Where LLMs Commonly Fail
LLMs are powerful but imperfect. Frequent failure patterns include:
- hallucinated facts
- dropped constraints from long prompts
- brittle formatting under schema pressure
- inconsistent behavior across paraphrases
- latency or timeout issues with long inputs
- bias or uneven quality across languages and user groups
8. What QA Teams Should Verify Before Trusting an LLM in Production
Before adopting an LLM for a real workflow, it helps to verify a few basic things deliberately:
| Area | What to verify | Why it matters |
|---|---|---|
| Context handling | Important instructions are not ignored or truncated | Long prompts often fail silently |
| Output structure | JSON, tables, or required formats are stable | Many AI workflows break in post-processing |
| Domain accuracy | Product terminology and business rules are preserved | Fluent language can still hide wrong logic |
| Behavioral consistency | Similar prompts produce similarly acceptable results | Prompt brittleness creates operational risk |
| Safety and boundaries | The model refuses unsafe requests without blocking valid ones | Over-refusal and under-refusal both matter |
QA/SDET Relevance
Manual QA should validate:
- whether the model actually used the provided context
- whether long prompts change answer quality
- whether domain terminology is understood correctly
- whether the answer remains useful across phrasing changes
QA automation and SDETs should validate:
- token budget edge cases
- schema compliance for structured outputs
- regression behavior across model or prompt changes
- latency, timeout, and fallback paths
- safety and refusal handling for risky prompts
Practical Work
Exercise: Build a Small LLM Capability Test Matrix
Objective: Evaluate an LLM as a product component instead of treating it like a magic box.
Pick one QA-oriented task, such as:
- generating API test cases
- summarizing a production defect
- converting acceptance criteria to BDD scenarios
Create 12 test cases across these categories:
| Category | Example |
|---|---|
| Short clean prompt | One requirement paragraph |
| Long prompt | Requirement plus logs plus edge-case notes |
| Ambiguous prompt | Missing one key business rule |
| Structured output | Require JSON or markdown table |
| Paraphrased prompt | Same task, different wording |
| Adversarial prompt | Add conflicting or distracting instructions |
For each test case, record:
- input size in rough token terms
- expected behavior
- acceptable variation range
- failure type if the model goes wrong
Reflection questions:
- Which failures came from missing context versus poor reasoning?
- Which checks could be automated reliably?
- Which output properties matter more than exact phrasing?
Key Takeaways
- LLMs process tokens, not human-friendly pages or paragraphs.
- Parameters, embeddings, and context windows affect behavior in different ways.
- Chat quality depends on both model architecture and fine-tuning style.
- Output is probabilistic, so evaluation must go beyond exact string comparison.
- QA teams need coverage for context limits, formatting reliability, and behavioral drift.
YouTube Resources

What this helps with: One of the clearest high-level explanations of tokens, training, inference, and why LLMs behave like probabilistic text engines.

What this helps with: Reinforces the high-level mental model of what LLMs are doing without jumping too quickly into implementation detail.
Next Step
Next, move into Transformers and Attention to understand the architecture that made modern LLMs practical at scale.